library(tidyverse)
library(readxl)
path = "Excel/640 Sum Between Two Pluses.xlsx"
input = read_excel(path, range = "A2:A21")
test = read_excel(path, range = "C2:D8")
result = input %>%
mutate(index = cumsum(Data == "+")) %>%
filter(Data != "+") %>%
summarise(sum = sum(as.numeric(Data)), .by = index)
all.equal(result$sum, test$Sum)
#> [1] TRUEExcel BI - Excel Challenge 640
excel-challenges
excel-formulas
🔰 Treat the data between two pluses as one group.
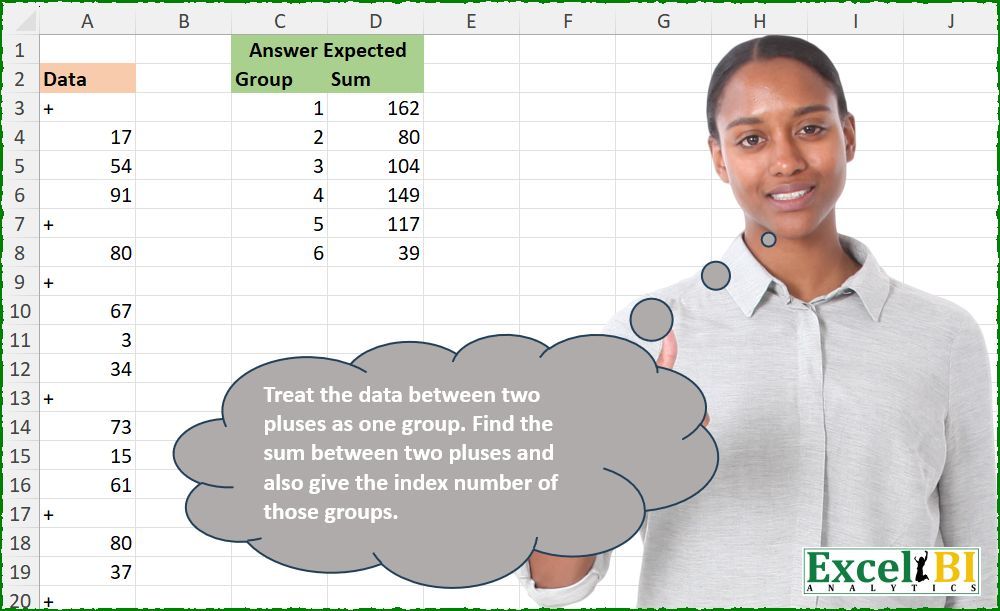
Challenge Description
🔰 Treat the data between two pluses as one group. Find the sum between two pluses and also give the index number of those groups.
Solutions
- Logic: Read the workbook ranges needed for the challenge; Derive the required intermediate columns; Aggregate or rank the data at the required grouping level.
- Strengths: The code maps the workbook rule into a compact, reproducible pipeline.
- Areas for Improvement: The solution assumes the workbook layout and selected ranges remain stable, so any structural change in the sheet would require small adjustments.
- Gem: The elegant part is how little code is needed once the correct intermediate representation is chosen.
import pandas as pd
path = "640 Sum Between Two Pluses.xlsx"
input = pd.read_excel(path, usecols="A", skiprows=1, nrows=20)
test = pd.read_excel(path, usecols="C:D", skiprows=1, nrows=6)
input['Group'] = (input['Data'] == '+').cumsum().astype('int64')
filtered = input[input['Data'] != '+']
result = filtered.groupby('Group').agg({'Data': lambda x: x.astype(float).sum()}).reset_index()
result.columns = ['Group', 'Sum']
result['Sum'] = result['Sum'].astype('int64')
print(result.equals(test)) # TrueThe Python version follows the same grouped logic and keeps the transformation explicit in a dataframe pipeline.
Difficulty Level
Easy / Medium
The business rule is clear, though the workbook still needs a few transformation steps to reach the expected output.